



AI 기술 고도화에 따라 고품질 데이터 수요가 빠르게 늘어나는 가운데, 크라우드웍스가 최근 수행한 고난도 LLM 학습 데이터 구축 사례를 공식 기업 블로그를 통해 공개했다.
이번에 공개된 주요 사례는 ▲인포그래픽 텍스트 매칭 데이터셋 ▲텍스트 기반 SQL 파인튜닝 데이터셋 ▲전문 의학지식 질의응답 데이터셋 등으로 AI 레디 데이터(AI-Ready Data)에 대한 높은 수준의 전문성과 데이터 설계 역량이 요구되는 프로젝트다.
이런 데이터는 단순한 텍스트 수집·라벨링·가공을 넘어서 도메인 전문 지식, 복잡한 논리 구조 분석, 텍스트와 이미지 정보 간의 의미적 일치성 확보 등이 필요하다. 이로 인해 일반 데이터 대비 단가가 20~30% 이상 높고, 숙련된 인력 확보와 체계적인 프로젝트 운영 및 검수 등 고도화된 품질 관리 역량이 필수적이다.
크라우드웍스 프로젝트 사례
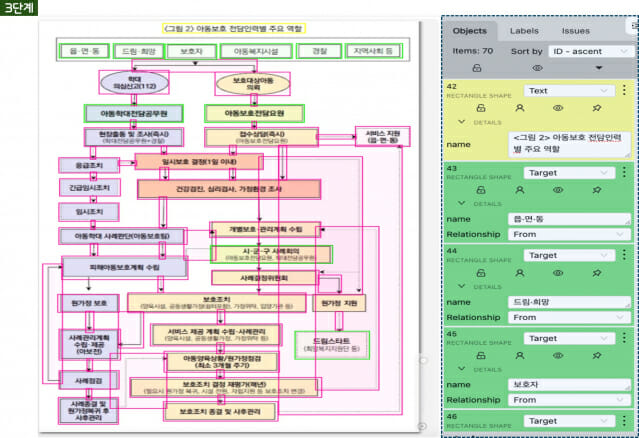
대표 사례인 '인포그래픽과 텍스트 매칭 데이터셋' 프로젝트는 도표·순서도·계층 구조 등 복잡한 시각 요소가 포함된 문서 이미지에서 구성 요소(컴포넌트)와 작업 단계(노드)를 식별하고, 각 요소를 설명하는 의미 단위 텍스트를 생성하는 고난도 과업이었다.
크라우드웍스는 데이터 일관성을 확보하기 위해 VLM(Vision-Language Model)을 활용해 이미지 설명문 생성을 자동화하고, 까다로운 검수 과정을 개선하고자 JSON 시각화 툴을 개발해 데이터 품질과 효율을 모두 확보했다. 그 결과 당초 4개월로 계획된 프로젝트를 3개월 만에 성공적으로 완료하며 기술력을 입증했다.
관련기사
- 민주당, 김홍일 방통위원장 탄핵 추진..."6월내 통과 목표"2024.06.27
- 김홍일 위원장 "2인 체제 방통위, 바람직하지 않지만 위법 아니다”2024.06.21
- LG 구광모 6년...AI·바이오·클린테크 키운다2024.06.28
- 화재 막는 배터리 진단기술 뜬다...민테크, 상장 후 존재감 '쑥쑥'2024.06.28





